在当今的互联网世界中,缓存服务的重要性不言而喻。它不仅提升了系统的响应速度,还极大地增强了用户体验。然而,随着业务的不断扩展,如何确保缓存服务的高可用性和稳定性,成为了我们必须面对的问题。今天,就让我们一起探讨一致性哈希如何成为解决这些问题的利器。
一、缓存集群的高可用性
缓存服务从单点扩展到集群后,缓存数据的分发问题变得尤为重要。假设我们有3台缓存服务器,每台服务器存储着不同的数据。那么,在更新缓存时,我们应该将新数据存储在哪台机器上呢?这就是缓存负载均衡策略要解决的问题。
目前,Redis流行的集群方案有官方Cluster方案、twemproxy代理方案、哨兵模式和Codis等。这些方案各有优缺点,但都为我们提供了一定的数据同步和扩展能力。
二、一致性哈希:解决缓存集群扩展的关键
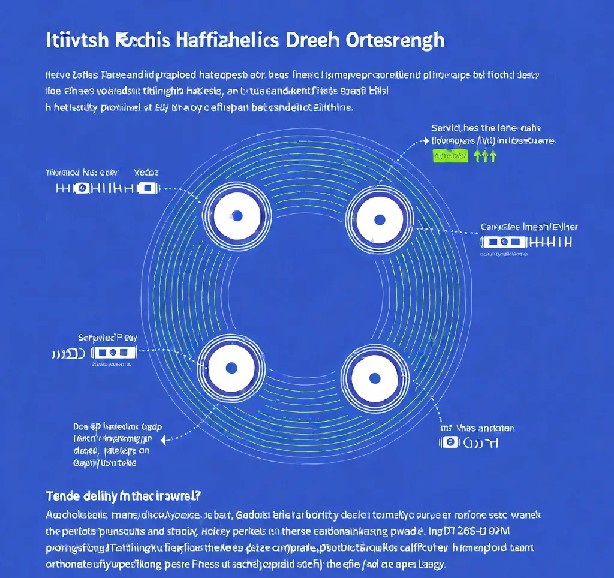
在负载均衡策略中,一致性哈希脱颖而出。它通过一个哈希环来实现数据的分布和路由,使得节点扩展时的数据失效或迁移量大大减少。
举个例子,假设我们有4台缓存服务器A、B、C和D。当有新的数据Key需要进行哈希操作时,我们会根据其hash值与服务器节点的hash值进行对比,然后顺时针找到最近的节点进行存储。这样,即使缓存服务器数量发生变化,数据迁移的范围也会被限制在最小范围内。
然而,一致性哈希也存在一个问题,那就是数据倾斜。当某些节点宕机时,与其相关的所有数据都会被转移到其他节点上,导致这些节点的流量激增,甚至可能出现缓存雪崩的现象。
三、如何解决数据倾斜问题?
为了解决数据倾斜问题,我们可以采用添加虚拟节点的方法。通过在原有的服务器节点上再添加一些虚拟节点,并对这些虚拟节点进行哈希操作,可以使得数据在各个节点上的分布更加均匀。
此外,还可以采用一致性哈希算法的变种,如虚拟节点一致性哈希或加权一致性哈希等,来进一步优化数据的分布和路由。
四、面试中的杀手级问题:实现一致性哈希
在面试中,面试官可能会要求你实现一致性哈希算法。以Java为例,我们可以利用TreeMap这个数据结构来实现一致性哈希。TreeMap基于红黑树实现,元素默认按照key的自然排序排列,对外开放了一个tailMap(K fromKey)方法,该方法可以返回比fromKey顺序的下一个节点,大大简化了一致性哈希的实现。
总之,一致性哈希作为一种高效的负载均衡策略,在缓存集群的高可用性和扩展性方面发挥着重要作用。通过合理地应用一致性哈希算法,我们可以有效地解决缓存数据的分发和路由问题,提升系统的稳定性和性能。
声明:
1、本博客不从事任何主机及服务器租赁业务,不参与任何交易,也绝非中介。博客内容仅记录博主个人感兴趣的服务器测评结果及一些服务器相关的优惠活动,信息均摘自网络或来自服务商主动提供;所以对本博客提及的内容不作直接、间接、法定、约定的保证,博客内容也不具备任何参考价值及引导作用,访问者需自行甄别。
2、访问本博客请务必遵守有关互联网的相关法律、规定与规则;不能利用本博客所提及的内容从事任何违法、违规操作;否则造成的一切后果由访问者自行承担。
3、未成年人及不能独立承担法律责任的个人及群体请勿访问本博客。
4、一旦您访问本博客,即表示您已经知晓并接受了以上声明通告。
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。
Copyright 2005-2024 yuanmayuan.com 【源码园】 版权所有 备案信息
声明: 本站非腾讯QQ官方网站 所有软件和文章来自互联网 如有异议 请与本站联系 本站为非赢利性网站 不接受任何赞助和广告